Where we're at
The bottleneck for long running agents is no longer the model.
It's the environment.
When you zoom in, autonomous agents are a simple runtime built on top of runtime primitives and WebSockets for communication via channels people already use everyday.
The magic is in the fact that the agent gets a "real" workspace.
Manus, Daytona, E2B and many others made it clear that the future of agents involves a personal computer aesthetic.
With this came the burden of execution and maintenance of the agent's workspace.
It didn't take long for me to crash out when I ran a long running task on a Daytona connection with a simple Python framework I wrote in 20 minutes.
Daytona was initially built for burst / spot workloads - not for long running / re-usable that need to live in their environment.
With the models of today and the always evolving harness that is openclaw, we can take a step back and look at what these environments actually need.
What does an agent sandbox actually need
When building companion-os (an agent computing architecture in Kubernetes) I had to think about a lot of things:
spin-up time, vertical auto-scaling (burst usage), pod isolation, network, disk mounting, gateway exposure, dev port exposure, pod-restart persistence, custom release based per-sandbox updates for the one day we decided to write our own openclaw
The whole spiel.
Kubernetes turned out to be the right framework
It's traditionally used for distributing consensus computation across thousands of nodes - but in our case it also us so many great features out of the box
pod isolation, vpa, autoscaler, and rolling updates out of the box.
The base load balancer might be kinda mid but it's very very close to perfect for the use case
About two days into building the sandboxing system I stumbled upon kube-sandboxes- a Python SDK that abstracts away the traditional controller / orchestrator layer and makes sandbox primitives into a CRD with pretty much everything I had spent the last 48 hours writing from scratch
Nice.
We needed a way to persist memory and storage through restarts (Kubernetes does not do this).
EFS fits perfectly in here.
It lets you mount a folder from a pod to a central AWS managed filesystem.
Per-user access points, gigabit-based billing.
Beautiful.
Pairing this with AWS Fargate - the cost picture gets very interesting.
With this I was able to drop our total cost to ~$3 / user / month.
Wild right?
High level
Here's what the stack looks like:
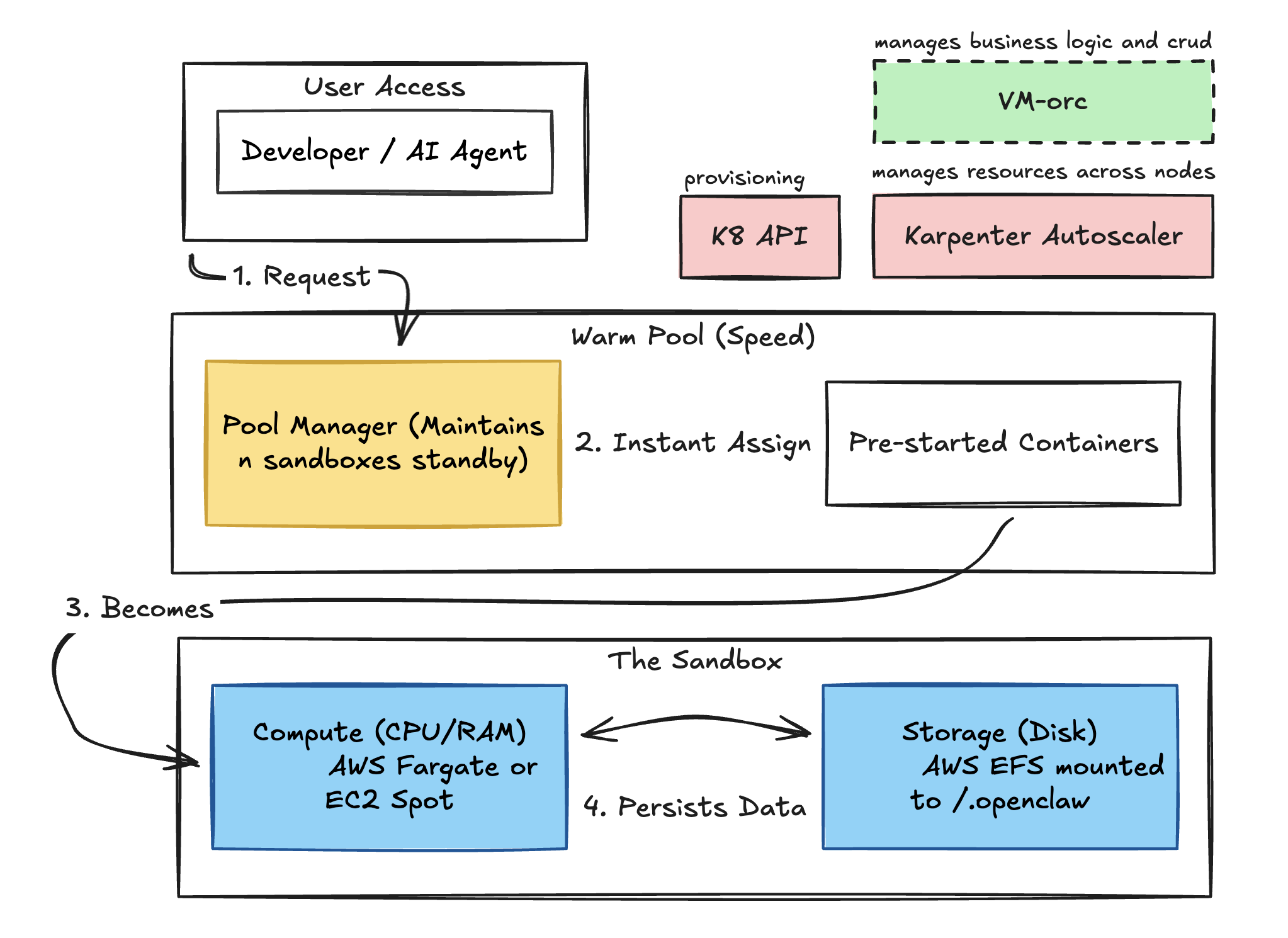
Each sandbox is an isolated Kubernetes pod with its own network policy, resource limits, and EFS-backed workspace.
I had to add a service layer for the business logic called the "vm-orchestrator" it's extremely simple, just a few api-muxes for CRUD operations on users and a reverse proxy for the user domain ("user.os.companion.ai") setup
The warm pool keeps ~10 pods pre-provisioned with the service running so new users can "spin up" in under 5 seconds instead of waiting for the image to mount.
Karpenter handles the node-level CPU scaling underneath automatically (Kubernetes base autoscaler is very slow).
The agent doesn't know or care about any of this infrastructure.
It just sees a filesystem, a network connection, its running processes, and the user/agent's message input.
agentikube
I ended up building something to abstract this away for others
Introducing agentikube, a Helm chart i created over the weekend
Instead of writing kubectl manifests by hand and wiring up EFS access points, you write a simple config file and run a couple commands to get everything online.
The config covers CPU compute (Karpenter instance types, spot vs on-demand), storage (EFS filesystem ID, reclaim policy), and sandbox settings (image, resource limits, warm pool size, network policy).
This feels like a great way to run a large scale agent swarms on a pointed task. Similar to what cursor did with their recent 1000 commits/hr experiment -
Conclusion
An agent that runs in a throwaway container with no persistent storage and shared network access is fundamentally limited.
It cannot accumulate context across sessions. It cannot install tools and keep them around. It's a cool demo but can't do much.
Give it an isolated persistent sandbox and suddenly the ceiling goes way up.
The agent can build up its workspace over time, maintain state across sessions, and operate without stepping on other agents. With everything tracked in Git.
The models will keep getting better.
The base harness will keep evolving.
But the environment is what lets agents go from "run a task" to "live in a workspace"